How to extract music sources: bass, drums, vocals and other ? – music separation with AI
07 Sep 2021
In this article I will show how we can extract music sources: bass, drums, vocals and other accompaniments using neural networks.
Before you will continue reading please watch short introduction:
Separation of individual instruments from arranged music is another area where machine learning algorithms could help. Demucs solves this problem using neural networks.
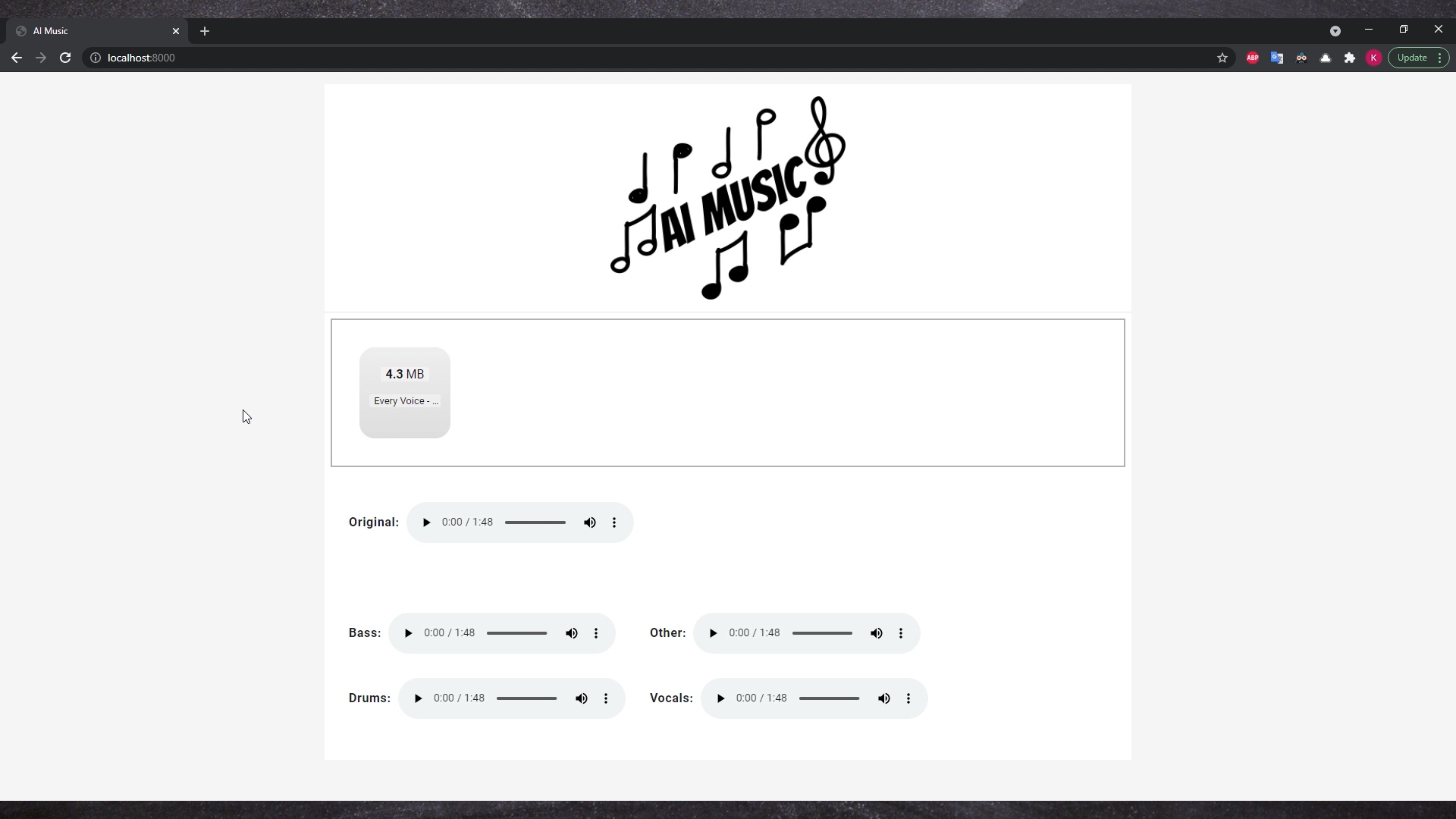
The trained model (https://arxiv.org/pdf/1909.01174v1.pdf) use U-NET architecture which contains two parts encoder and decoder. On the encoder input we put the original track and after processing we get bass, drums, vocals and other accompaniments at the decoder output.
The encoder, is connected to the decoder, through additional LSTM layer, as well as residual connections between subsequent layers.
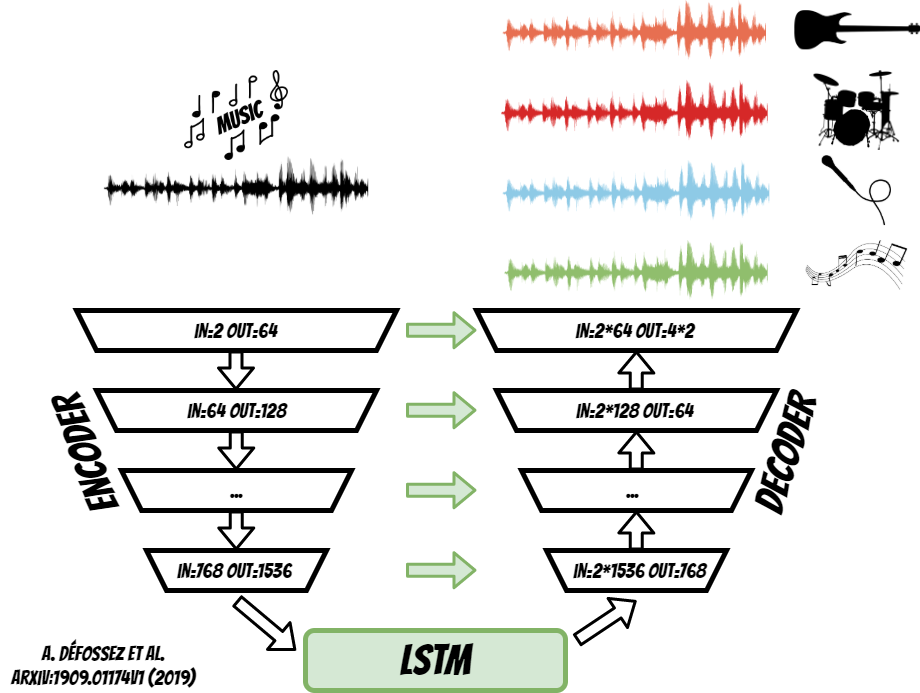
Ok, we have neural network architecture but what about the training data ? This is another difficulty which can be handled by the unlabeled data remixing pipeline.
We start with another classifier, which can find the parts of music, which do not contain the specific instruments, for example drums. Then, we mix it with well known drums signal, and separate the tracks using the model.
Now we can compare, the separation results, with known drums track and mixture of other instruments.
According to this, we can calculate the loss (L1 loss), and use it during the training.
Additionally, we set different loss weights, for known track and the other.
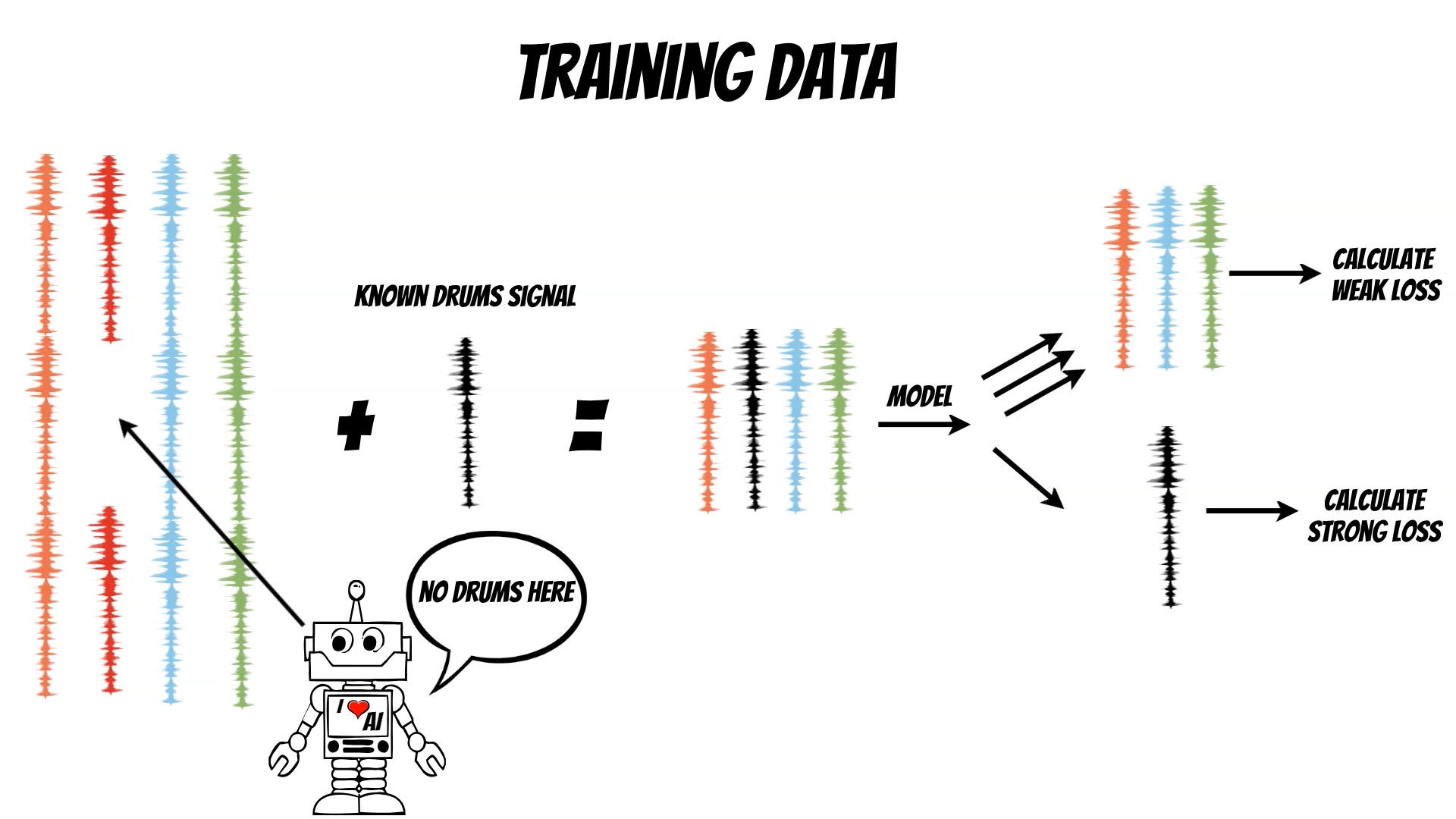
The whole UI is kept in the docker image thus you can simply try it:
#for CPU
docker run --name aiaudioseparation -it -p 8000:8000 -v $(pwd)/checkpoints:/root/.cache/torch/hub/checkpoints --rm qooba/aimusicseparation
#for GPU
docker run --name aiaudioseparation --gpus all -it -p 8000:8000 -v $(pwd)/checkpoints:/root/.cache/torch/hub/checkpoints --rm qooba/aimusicseparation